What effect do stemming, lemmatizing, and removing stop words have on text data?

If you’re getting into data science and you’re still fuzzy on the difference between structured and unstructured data…do an NLP project.
“NLP” is natural language processing. Until I did an NLP portfolio project, it wasn’t that clear to me just how much processing text needs to go through in order to be interpretable as data.
Say you want a model to classify individual tweets as about a disaster (class 1) or not about a disaster (class 0). A naïve way to go about it would be to create a rule-based model that labels a tweet as class 1 simply if it contains certain words like “fire” or “explosion.” But look at the two tweets below.


Language is messy, but any human who’s literate in English can easily tell that one tweet is about a disaster, while the other is not. A machine, however, would need some more help.
Here are some examples of processing steps that text can go through in order to be given enough “structure” to be used as machine learning input:
- Tokenization
- Stemming
- Lemmatization
- Removing stop words
- Vectorization
- Count
- Binary
- TF-IDF
- Part-of-speech tagging
- Named-entity recognition
- Meta-feature extraction
These are just some examples of NLP steps. Take a look at how they’re applied to one tweet below:
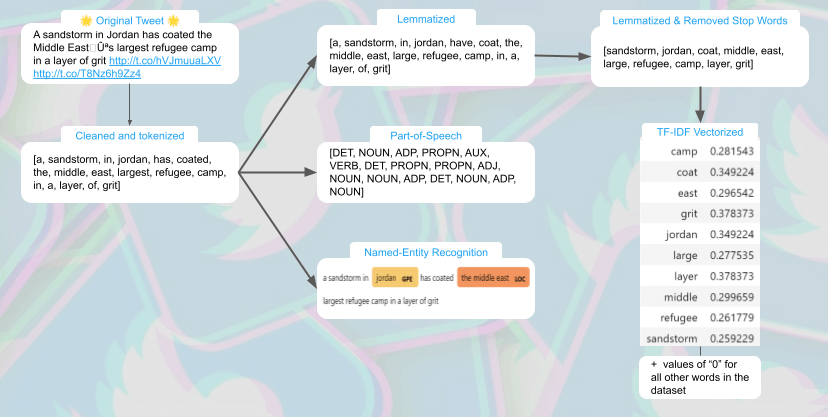
As you can see, giving text “structure” in the eyes of a machine learning model looks like you’re chopping it up, boiling it, then taking an MRI scan of the result. The tweet can become almost unrecognizable. But the point is to extract hidden patterns from the text that might allow an algorithm to discern whether it is from one class or another.
Stemming, Lemmatization and Stop Words
I’m going to focus the rest of this blog post on the effect that stemming, lemmatization, and removing stop words can have on text data. You can read a more thorough explanation of these concepts here and here courtesy of Stanford University, but I’ll give brief definitions below:
- stop words: These are the most common words in a language and often don’t add much useful information in a data context. These are words like “the,” “and,” “with,” “for,” “a,” or “it,” “to,” or “is.”
- stemming: This is a practice where words are normalized by chopping off prefixes and suffixes in order to convert a word into its “stem.”
- lemmatization: This is a more complex way to normalize words than stemming. Lemmatization looks at the grammatical context of a word to reduce it down to its base form, usually a noun.
If the difference between stemming and lemmatization is still unclear, look at the following example. The original sentence will be stemmed using the NLTK library and lemmatized using the SpaCy library. Pay close attention to what’s happening to the versions of the word “best.” In stemming, the outcome is the same token every time (“best”); in lemmatization, the outcome depends on whether the word is being used as a noun or a verb.
| Original | “I’m the best. I bested them all in the race. I love winning.” |
| Stemmed | “i’m the best i best them all in the race i love win” |
| Lemmatized | “i be the good i best they all in the race i love win” |
Distinguishing Classes Using Stemming, Lemmatization, and Stop Words
You might still be wondering what use these concepts have in classifying a tweet as a disaster tweet or not.
The graphs below show the 20 most common words in the Kaggle dataset: Natural Language Processing with Disaster Tweets, when separated by class. I made six different versions of these charts:
- Tokenized
- Tokenized + removed stop words
- Tokenized + stemmed
- Tokenized + stemmed + removed stop words
- Tokenized + lemmatized
- Tokenized + lemmatized + removed stop words
Take note of how many words there are in common between the disaster and non-disaster classes.
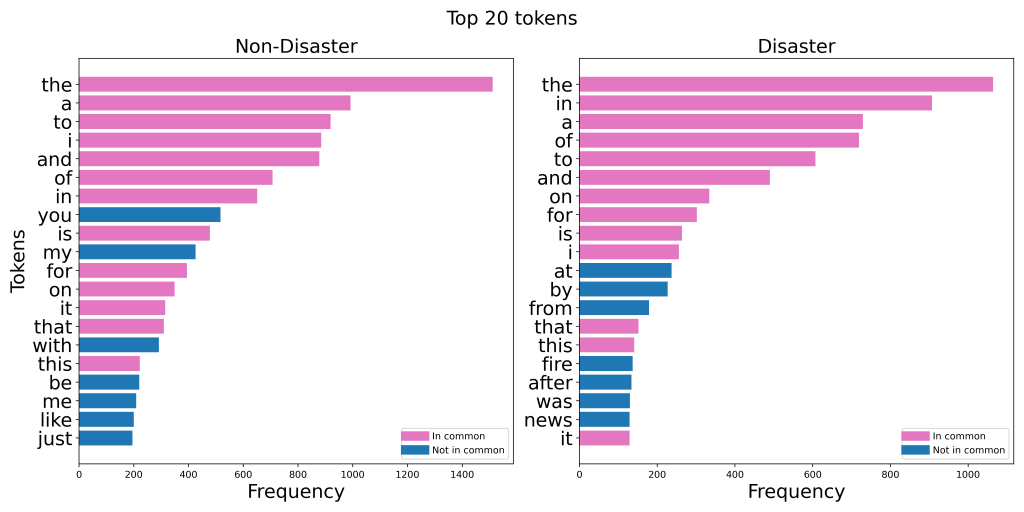
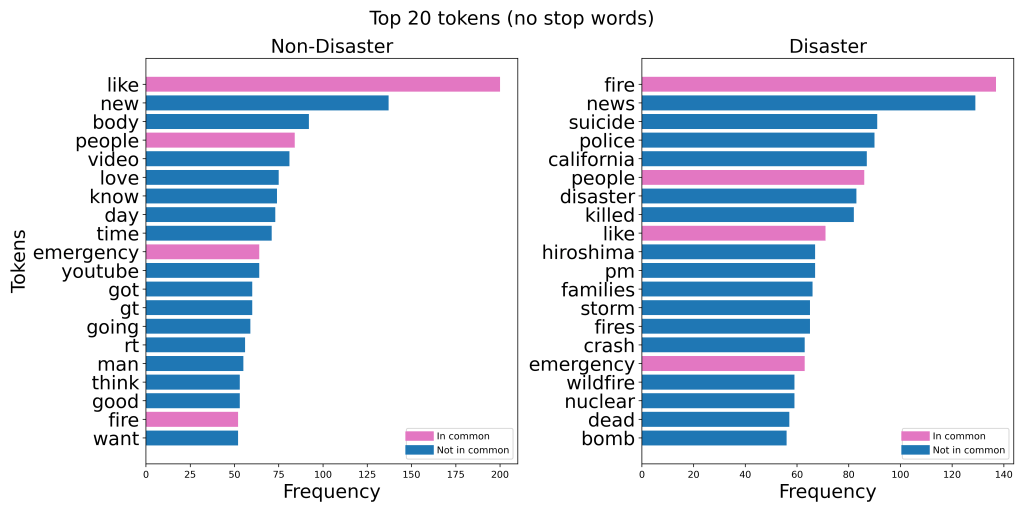
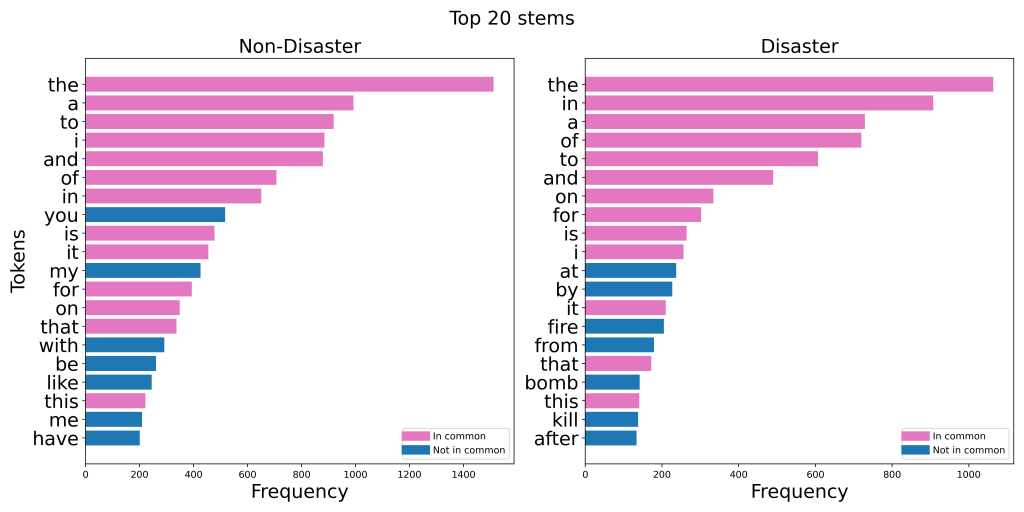
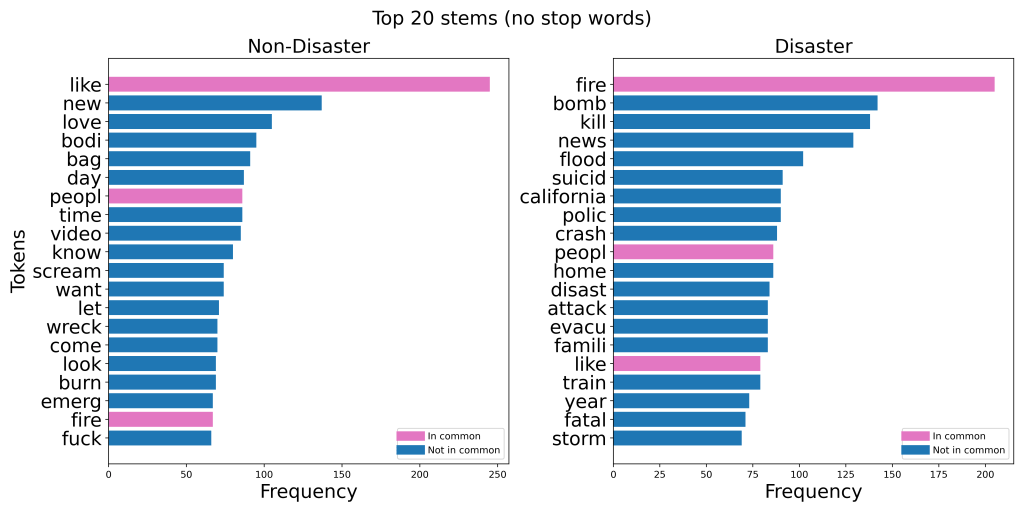
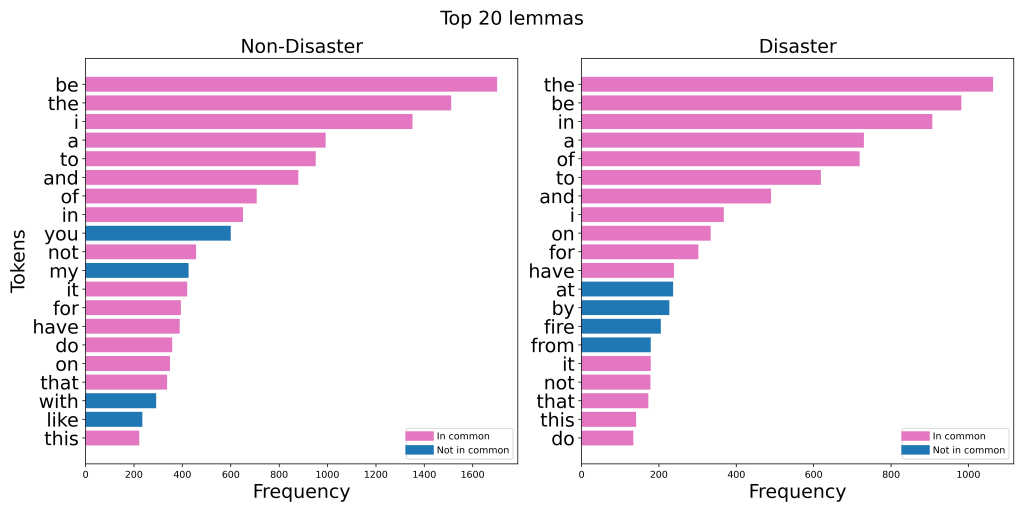
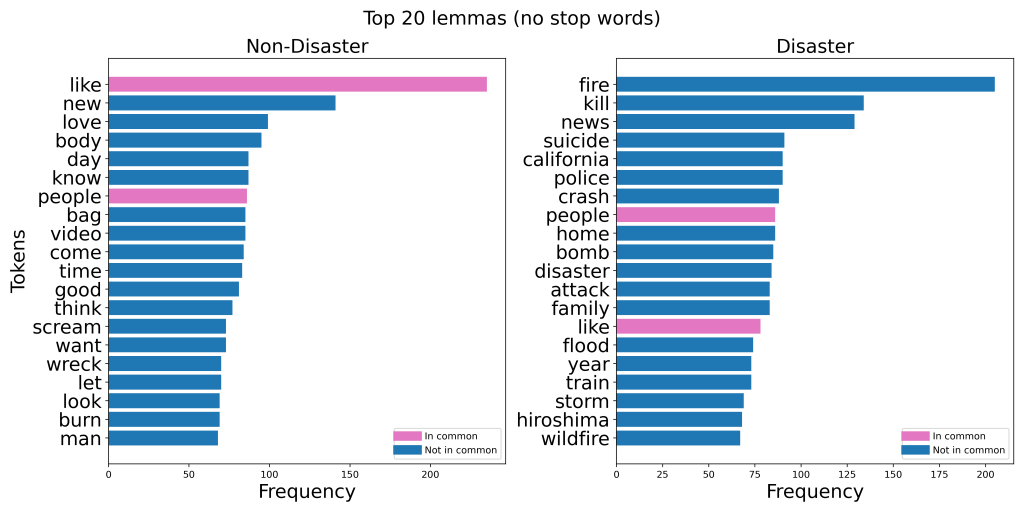
In each version, removing stop words made the two classes way more distinguishable. In the case of lemmatization, the top 20 list went from having 16 words in common to having just two words in common!
Stop words can come in handy, though. In my NLP project, one feature I engineered was the proportion of stop words in each tweet.
Lemmatization is usually considered more accurate than stemming. In fact, the SpaCy library, which is newer than NLTK, doesn’t even have stemming capability.
But stemming also has an advantage: it’s much quicker and requires less processing power than lemmatization. In my project, lemmatizing the entire dataset would usually take around two minutes, while stemming took just a few seconds. If you’re dealing with a problem where grammatical context is less important, stemming might be the way to go.
